在人工智能技术高速迭代的今天,大语言模型的参数规模不断刷新纪录,但一个根本性缺陷始终如影随形——
一、痛点切入:为什么需要联网技术?

传统的AI对话依赖模型自身的“闭卷知识”——即预训练阶段固化下来的参数化记忆。这意味着当你询问“今天北京天气”“某只股票最新收盘价”或“最近出台的政策”时,模型要么拒绝回答,要么基于过期数据编造不准确的信息。这种“只懂过去、不懂现在”的局限,严重制约了AI在资讯获取、市场分析、实时决策等场景中的应用价值。
更值得关注的是,传统引擎虽然能提供海量实时信息,但返回的是“链接列表”,用户需要逐一点击、阅读、甄别、总结,信息获取效率极低。用户在两种方式之间被迫做出选择:要么接受AI模型的知识延迟,要么承受手工检索的高认知负担。
联网技术的设计初衷,正是为了打破这一困境——让大语言模型能够动态调用互联网引擎获取最新信息,并整合这些信息来生成结构化的、可直接阅读的答案-11。这是从“知识记忆”到“知识检索”的范式跃迁。
二、核心概念讲解:检索增强生成(RAG)
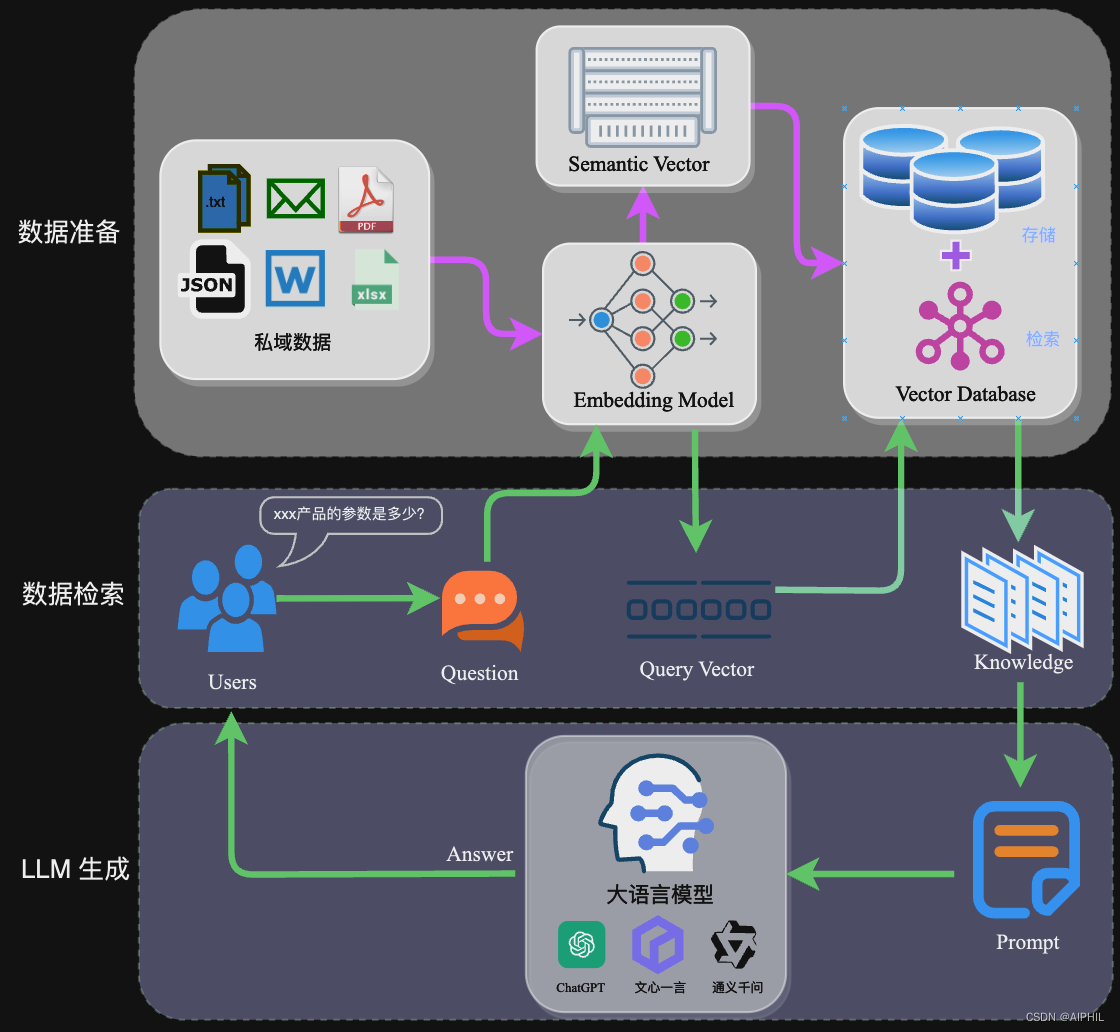
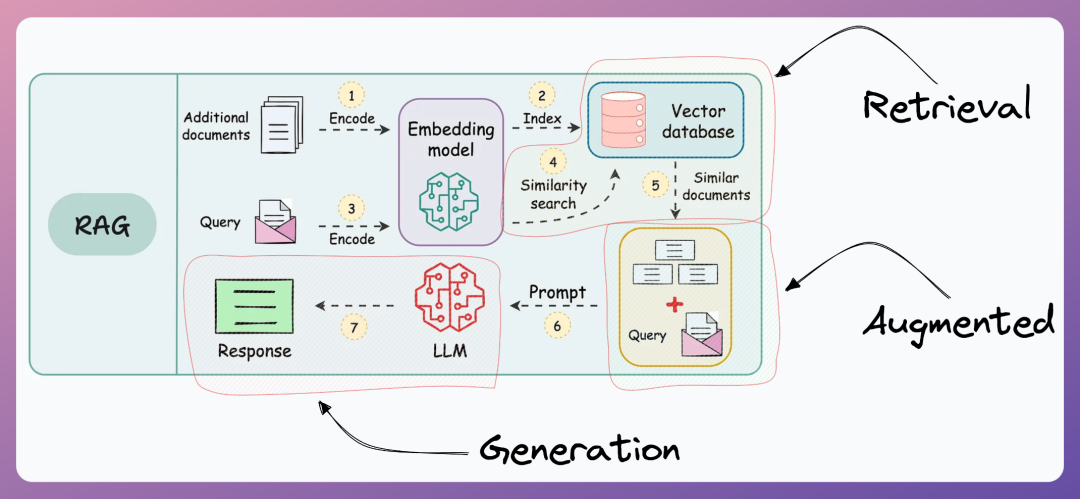
检索增强生成(Retrieval-Augmented Generation,RAG) ,是一种将信息检索与文本生成深度融合的技术框架。拆解关键词:检索(Retrieval) 指从外部知识源中获取相关信息片段;增强(Augmented) 指将这些片段注入到生成模型的上下文中;生成(Generation) 指大模型基于增强后的上下文输出答案-。
生活化类比:把RAG想象成一场“开卷考试”。传统的大模型就像一个只复习了教材的考生,遇到教材没覆盖的问题就束手无策;而RAG相当于允许考生在考试过程中翻阅图书馆资料——拿到题目后先去图书馆查找相关文献,再结合文献和自己的理解写出答案。结果是更准确、更全面、可溯源。
RAG解决的核心问题是知识边界扩展与幻觉抑制。传统的LLM生成内容时可能“凭空编造”(即AI幻觉),而RAG将生成内容严格约束在检索到的证据之上,从根本上降低了幻觉发生率。
三、关联概念讲解:大模型联网
大模型联网(Large Model Web Search) ,是指大语言模型通过实时调用互联网引擎获取最新信息,并整合这些信息来生成回答的功能-11。它是RAG技术在实时公网场景下的具体应用。
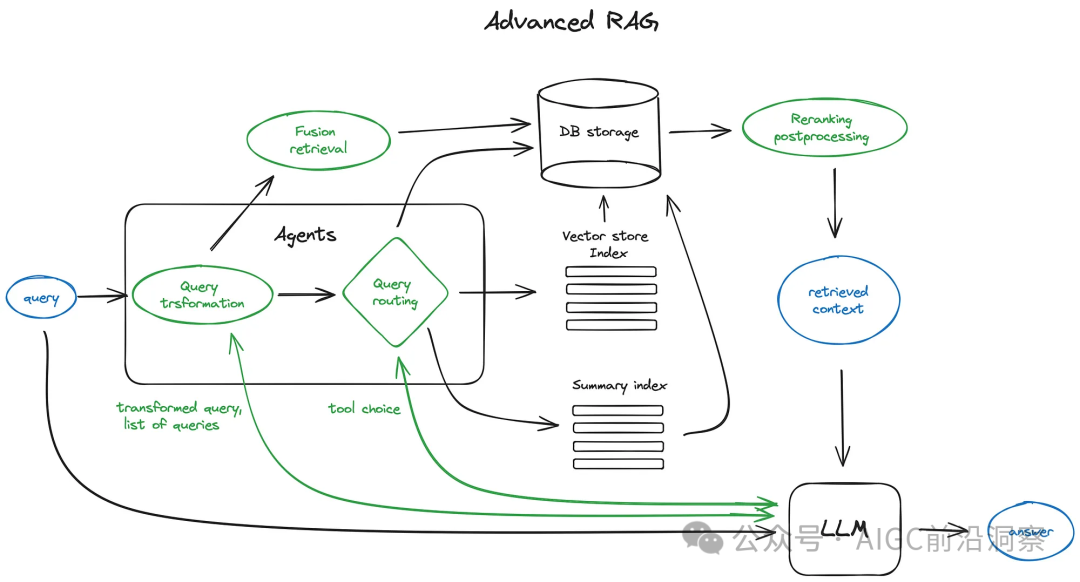
联网与RAG的关系:RAG是“思想”,联网是“实现方式”。RAG定义了一种“检索+生成”的通用方法论,而联网则是这一方法论在“互联网实时信息”这个特定知识源上的落地——用引擎API代替向量数据库,用网页抓取代替本地文档检索。
关键区别:
| 维度 | RAG(通用版) | 大模型联网(海螺AI版) |
|---|---|---|
| 知识来源 | 企业知识库、内部文档、结构化资料 | 互联网公开实时信息(新闻、天气、股价等) |
| 检索方式 | 向量化检索(如FAISS),基于语义相似度 | 调用引擎API(如Bing/Google),基于关键词+语义 |
| 典型场景 | 专业问答、客服系统、文献检索 | 实时资讯查询、市场动态、突发事件 |
| 数据更新频率 | 取决于知识库刷新策略 | 毫秒级实时 |
海螺AI的联网不仅支持公网实时信息检索,还能与RAG向量检索形成互补——即“公网+私域”双路知识获取。当用户询问“2026年AI市场的最新趋势及公司内部相关政策”时,系统可以并行检索互联网实时资讯和内部知识库,整合后生成完整答案-14。
四、概念关系与区别总结
一句话概括:RAG是“检索增强生成”的设计范式,联网是这一范式在实时公网数据源上的具体工程落地;RAG回答“检索什么”,联网回答“从哪里检索”。
逻辑关系图:
RAG(通用框架) ├── 知识源A:本地向量数据库 → 企业知识问答 ├── 知识源B:互联网引擎 → 海螺AI联网 └── 知识源C:结构化API → 天气/股票查询
记忆口诀:“RAG定方法,联网定路径;公网实时搜,答案可溯源。”
五、代码 / 流程示例演示
以下是一个极简的联网+RAG流程模拟示例,用Python展示核心逻辑。海螺AI的后端实现与此高度一致。
import requests from typing import List, Dict def search_web(query: str) -> List[str]: """模拟引擎API调用,获取实时信息""" 实际调用中会使用Bing/Google等引擎API 海螺AI使用Heluo-Search Pro等联网模型 print(f"[检索] 正在: {query}") return [ "根据最新报道,2026年全球AI市场规模预计达48.5亿美元。", "Gartner预测,到2026年传统引擎量将下降25%。" ] def rag_generate(query: str, search_results: List[str]) -> str: """RAG生成:将检索结果嵌入Prompt,调用LLM生成答案""" prompt = f""" 用户问题: {query} 检索到的参考资料: {chr(10).join(f'- {r}' for r in search_results)} 请基于上述参考资料回答问题,并在答案中标注信息来源。 """ 调用大模型API生成答案(实际调用MiniMax MoE模型) return f"基于最新信息:{';'.join(search_results)}。建议关注市场动态。" def hailuo_search_pipeline(user_query: str) -> str: """海螺AI联网完整流程""" Step 1: 查询意图识别——判断是否需要联网 if any(kw in user_query for kw in ["最新", "今天", "实时", "2026"]): print("[路由] 检测到时序关键词,触发联网模式") Step 2: 执行联网检索 search_results = search_web(user_query) Step 3: RAG增强生成 answer = rag_generate(user_query, search_results) Step 4: 返回带溯源信息的答案 return answer + "\n\n[信息来源:互联网实时检索]" return "[路由] 无需联网,使用模型闭卷知识库响应" 示例调用 print(hailuo_search_pipeline("2026年AI市场的最新趋势是什么?"))
执行流程说明:系统首先识别用户问题中的时效性关键词(如“最新”“今天”),决定是否触发联网;若触发,则通过引擎API获取相关网页内容,经解析、去重、排序后构建增强Prompt,再由大模型生成带溯源标注的答案-11。海螺AI网页版和APP端均提供“联网”按钮,用户可手动开启或设置默认联网-1。
六、底层原理 / 技术支撑
海螺AI联网能力的底层技术栈,建立在以下几个关键组件之上:
MoE(混合专家)大模型:海螺AI基于MiniMax自研的万亿参数MoE大模型,通过动态路由层将不同任务分流至对应的专家子网。例如,联网任务会激活语义解析与检索增强相关的计算路径,而非创作生成路径-2-27。
查询理解与意图识别:使用BERT等模型分析用户查询的深层意图,识别时间敏感词(如“最新”“实时”)、领域关键词和地域特征,通过二分类模型判断是否触发联网-11。
混合检索引擎:并行调用多个引擎API(如Bing/Google),通过“首包优先”策略控制延迟在200毫秒以内;对网页内容进行多模态解析(文本、图片、视频帧)与可信度评分-11。
知识蒸馏与上下文构建:对多个来源的检索结果进行去重(SimHash算法)、矛盾检测,再通过滑动窗口机制组装上下文注入大模型生成流程-11。
防幻觉与溯源标注:通过事实性约束对比检索摘要与生成内容的一致性,确保答案可验证;在输出中嵌入引用标记,用户可以点击查看信息来源-11。
这些底层技术并非孤立运作,而是通过“查询理解→混合检索→蒸馏整合→生成增强→溯源标注”的完整链路协同配合,共同支撑海螺AI的联网功能。
七、高频面试题与参考答案
Q1:请简述RAG(检索增强生成)的原理及其核心价值。
参考答案:RAG是一种将信息检索与文本生成深度融合的技术框架。其核心原理是:当收到用户问题时,先从外部知识源(如向量数据库或互联网)检索相关信息片段,然后将这些片段与原始问题共同构造成Prompt,输入大模型生成最终答案。核心价值体现在:①突破模型知识边界,引入实时或专业信息;②降低AI幻觉,答案基于检索证据;③支持信息溯源,增强可信度。
Q2:大模型联网与RAG有什么区别?
参考答案:RAG是通用设计范式,定义“检索+生成”的方法论;联网是RAG在实时公网数据源上的具体实现。区别在于:RAG的知识来源可以是企业内部文档、向量数据库等私域数据,而联网的知识来源是互联网公开实时信息;RAG通常使用向量检索,联网则依赖引擎API调用。
Q3:海螺AI是如何实现联网时降低延迟的?
参考答案:主要采用三种策略:①并行调用多个引擎API,通过“首包优先”策略获取最快返回结果;②对高频查询使用缓存(如Redis)存储结果,TTL通常设为1小时;③采用轻量化模型进行查询路由预判,避免不必要的联网检索开销。
Q4:请解释MoE模型如何支撑海螺AI的多任务处理能力。
参考答案:MoE(Mixture of Experts)通过动态路由层将不同任务请求分流至对应的专家子网,每个专家子网专注于特定类型任务(如创作、、分析)。海螺AI与星野APP共享同一底层MoE模型,但路由策略不同——高密度信息处理任务导向低温度值(<0.3)的逻辑解析子网,情感交互任务则导向高温度值(>0.8)的情感建模子网,实现资源的最优分配。
Q5:大模型联网如何防止“幻觉”现象?
参考答案:主要采用三重机制:①事实性约束解码,要求生成内容与检索摘要的匹配度不低于预设阈值(如80%),否则触发重试;②多源交叉验证,对来自不同渠道的检索结果进行矛盾检测和优先级排序;③溯源标注,在生成答案中嵌入来源链接,便于用户自行核验。
八、结尾总结
回顾全文,我们围绕海螺AI助手的联网能力,梳理了以下核心知识点:
技术痛点:传统AI存在知识时效性滞后,联网通过动态调用实时信息解决这一问题。
核心概念:RAG(检索增强生成)是“检索+生成”的设计范式,联网是其在公网场景的具体实现。
关系总结:RAG定义方法,联网定义路径;二者互补而非互斥。
原理要点:底层依赖MoE大模型、查询理解、混合检索、知识蒸馏和防幻觉机制。
面试重点:RAG原理、联网与RAG区别、延迟优化策略、MoE路由机制、防幻觉手段。
易错点提醒:切勿将“联网”与“RAG”混为一谈——前者是后者的具体应用形式,而非等同概念。面试中若能清晰区分二者的层级关系,将是加分项。
后续可继续深入探讨海螺AI的多模态能力(视频生成、语音通话)及其在影视创作、智能客服等行业的落地实践。