上周五下午,我接到一个兄弟伙从重庆打来的电话,他那个声音听得出来是真的要炸了。“我这个月第三回了,甲方丢给我二十多个合同扫描件,全是一个接一个的图片混在一起的PDF,页码乱七八糟有的还是歪的!我挨个去截图、识别文字、手动复制黏贴,搞了一下午,头都是大的!”说实话我听完一点不意外,因为三个月前我自个儿也是这个状态——桌面上散落着上百个没名字的PDF,想找一份上个月的研究报告得翻半天,那种感觉就像在老家柜子里找一只袜子,翻得鸡飞狗跳就是找不着。
后来是怎么翻身的?说起来简单得像个玩笑——我无意中在一个文档工具里发现了AI助手的入口,抱着“反正都这样了不如让机器试试”的心态点了一下,结果一发不可收拾。现在我每天处理的文档至少翻了三倍,但加班时间反而少了。今天就跟大家唠唠我折腾出来的这些心得,看看AI到底怎么帮你收拾那些烂摊子。

从“人找文件”到“文件自己跑过来找你”
先说说最让人头秃的事情:你明明记得某份文档里有句特别重要的话,但死活搜不到。我去年写年终总结的时候,要把三份不同版本的项目报告里头的关键数据抽出来拼在一起,那份报告统共将近四百页,我翻了整整一个周末都没搞利索。后来我用了某个带AI助手的PDF工具,直接给它一句指令:“把这三份报告中关于第四季度销售额的全部数据整理成一个表格。”


某金融机构的数据挺能说明问题,他们在合同审核上用AI辅助,单份合同的处理时间直接从90分钟压到了15分钟,合规审查的响应速度提升了三倍-4。你想啊,本来要喝两杯茶才能搞定的活,现在刷几条短视频的功夫就干完了,这个差距谁用谁知道。
扫描件再也不用一个个去认了
朋友遇到的那种合同扫描件乱成一锅粥的情况,其实最核心的问题就是文字识别。传统OCR工具以前用起来那叫一个痛苦——表格歪了识别不准,手写的批注基本等于白搭,打印模糊的页面更是重灾区。但现在的AI助手在这方面简直开了挂。我最近在用一个工具,它内置的DeepSeek-OCR在处理多页PDF的时候,不仅能读取文字,还能保留表格结构、标题层级和多栏排版这些重要信息,不会把你辛辛苦苦排好的版给弄散了-21。
还有Filez文档智能体那个方案更猛,用的是“OCR视觉识别+NLP语义理解”的双引擎架构,连倾斜三十度的纸质扫描件、带折痕的老旧文档都能精准定位文本区域,字符识别准确率稳定在98.8%以上-4。我自己试过把手头一份皱皱巴巴的旧合同扫描件丢进去,它把里面那些手写的边注都给提取出来了,当时第一反应是“靠,这玩意儿比我想象的聪明多了”。
大批量文件怎么治?别急,它能帮你一锅端
有人说“我就一两个文件,用AI是不是浪费了?”我跟你说,等文件一多你就懂了。前几天我接手一个项目,要做文献综述,手头攒了四十多篇PDF论文。以前这个活我得一篇一篇打开、看摘要、标记重点,然后再汇总——两三天能搞完算快的。结果那天我用
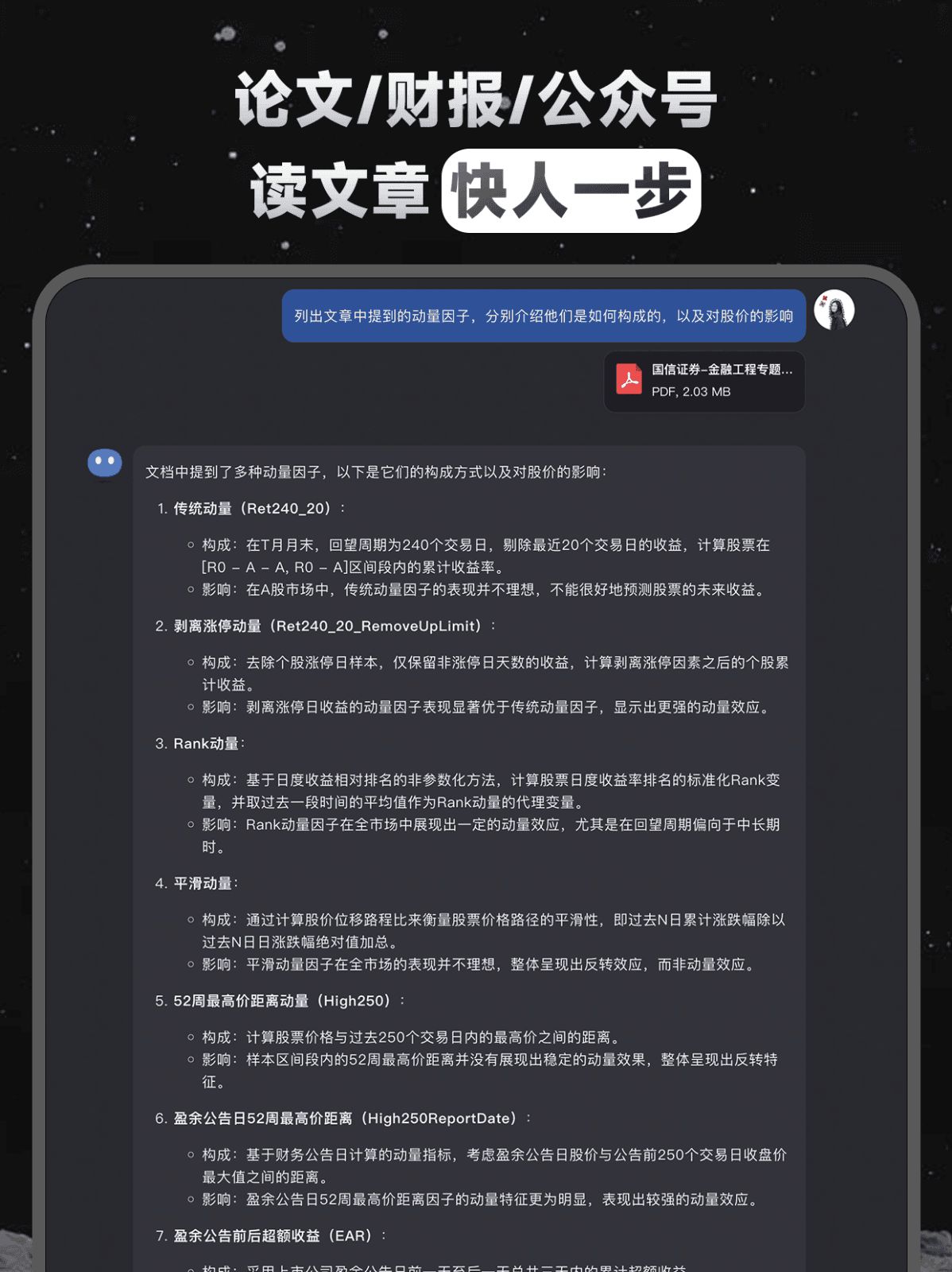
某制造企业也有个特别典型的例子,他们把三十万份纸质图纸用AI快速数字化,存储成本降低了七成五不说,检索效率还提升了九成-4。这就是说,那些你以为要花几辈子时间去整理的烂摊子,AI一出手可能就是几顿饭的功夫。
那些让你抓狂的小问题,其实都有解
还有一个痛点我想很多人都有:PDF里有些图表特别复杂,你想分析数据但又不愿意手动去算。Adobe Acrobat Studio的那个生成式演示功能,可以让你直接从多个PDF文件和网页里抽取信息,一键生成带幻灯片大纲的演示文稿,甚至还能生成一个播客风格的音频摘要-3。这玩意儿特别适合那种“老板说今天下班前给我一个PPT但我脑子还是一片空白”的场景。
另外如果你经常要看外文PDF,AI助手的翻译功能也相当能打。UPDF AI支持双栏对照翻译和逐页翻译两种模式,还能解释专业术语-16。我看德文文献的时候就靠这个救命——以前翻一页查两次词典的苦日子,总算熬出头了。
老实说,它也不是神仙
吹了半天也得说实话,

但话说回来,这个辅助程度已经远远超出我当初的预期了。以前一天只能干三件事,现在同样的时间能干八件事——而且不是干得糙,是干得更利索。那份被逼疯的朋友上周给我发消息,说他按我说的方法试了一下,合同扫描件处理完干净得像打印机刚吐出来的一样,他终于有时间准点下班接孩子放学了。
所以啊,别再把时间浪费在那些重复、机械、毫无技术含量的文档整理上了。让AI去跟PDF干仗,你腾出手来干点更有价值的事情——比如琢磨琢磨这个周末到底去哪儿吃顿好的。
网友问答
网友“小强快跑”提问: 我看你说的这些功能心动了,但市面上打着AI旗号的PDF工具有一大堆,到底怎么选才能不踩坑?我是个个体户,预算有限,不想为了一堆我用不上的功能花冤枉钱。
回答: 这个问题问得太好了,说实话我刚入坑的时候也踩过几个大坑。我给你一个特别实在的判断标准:先想清楚你最头疼的是哪个环节。如果只是需要快速理解PDF内容,比如看合同、读论文、做笔记,那你其实用网页版的ChatPDF或者UPDF AI就足够了,这两种工具的免费版每天能处理三到五个PDF文件,上传限制分别是10到100兆-31。如果你像我朋友那样经常要处理扫描件、旧图纸,那就要优先选带强力OCR识别的工具,比如Filez或者有DeepSeek-OCR支持的平台。另外给你一个避坑小贴士:下单之前先去工具的官网或者社交媒体账号上看一下用户评价,尤其是那种“PDF内部页面混乱时识别率如何”的反馈,比官方宣传稿靠谱一百倍。个体户用的话,不建议一开始就买年费会员,先薅免费额度试用一两周,确定它确实能解决你的问题再掏钱,千万别像我当初那样脑子一热就充了一年的VIP——结果发现那个工具根本不适合我的文件类型。
网友“北京老周”提问: 我是个做财务的,每个月要处理几百张报销单和银行回单的PDF,很多都是手机拍的,光线不好、角度歪、有的甚至上面有手写字。我之前试过免费的OCR软件,但出来的内容乱成一团,根本不能用。AI助手能搞定这种又脏又乱的文件吗?要是识别错了,责任算谁的?
回答: 老周你这个情况太典型了,财务岗确实是PDF重灾区。答案是:能搞定,但得选对工具。你需要的不是那种“读PPT”的轻量级AI,而是带有“多模态识别”能力的文档智能体。Filez那种采用CTPN文本定位和EAST像素级分割技术的工具,即使是倾斜三十度、有折痕的纸质扫描件,字符识别准确率也能保持在98.8%以上-4。如果是银行回单那种固定版式的文件,准确率还能更高。但你问的那个问题特别关键——责任归属。我给你的建议是:永远不要完全依赖AI的识别结果来做最终决策。尤其是涉及金额、日期、收款人这些关键字段,你把AI提取出来的数据跟原始扫描件做一次人工交叉核对,花不了三分钟,但能杜绝所有隐患。我认识一家城商行做合同审核就是这么操作的:AI把二十三类关键字段抽出来,法务人员只核对那些系统标注“置信度低于95%”的项目,其他直接过——既保效率又保安全-4。
网友“在校研究生小李”提问: 我最近在写毕业论文,参考文献有一百多篇,全是PDF。我现在的方法是每天看三五篇,把重点复制到Word里,感觉明年毕业之前都看不完。你说的AI助手能同时处理这么多文件吗?会不会把我的笔记弄丢或者搞混?
回答: 小李啊,你这个情况我太懂了,写论文的时候最痛苦的就是文献管理。好消息是,现在的AI助手完全能搞定你这个量级的文件。我之前看到中关村科金那边有个测评数据,支持自动标签分类的AI知识库系统,可以直接帮你减少百分之七十以上的人工整理成本,一百页的文档几秒钟就能完成核心信息提取,准确率超过九成-33。而且现在很多AI助手都支持“项目聊天”功能,你可以把所有文献PDF丢进一个项目文件夹里,然后问它“这个项目中有哪些文献提到了某某理论”,它会把相关的段落和文献来源一起列给你,不会混-16。至于笔记会不会丢,我建议你养成一个习惯:用AI助手生成摘要和标注之后,把它导出来的内容再备份到你自己的笔记软件里。我一般用UPDF AI或者万兴PDF处理完一批文献,会把每个PDF的AI聊天记录复制到飞书文档或者Notion里,这样就算换了设备换了工具,我的劳动成果也跑不掉。相信我,用这个方法你一个月能啃完那些文献,还能腾出时间好好把论文正文写一写。