从AlphaGo战胜李世石至今已有十年,下棋AI助手早已不再是顶尖棋手的专属训练工具,而是走进了普通爱好者的日常生活。当你打开一个围棋分析软件,看着AI实时标注的胜率曲线和推荐选点;或者打开一个象棋教学App,与自适应难度的AI对手对弈——背后支撑这一切的,正是以
很多人对下棋AI助手的理解停留在“它能赢我”的层面,却说不清它凭什么能赢。

一、痛点切入:传统棋类程序为什么不够“智能”?
先看一个最基础的传统棋类程序长什么样。

传统实现:纯Minimax + 手工评估函数
传统中国象棋AI的简化示意 def minimax(board, depth, is_maximizing): if depth == 0 or game_over(board): return evaluate_board(board) 手工定义的评估函数 if is_maximizing: max_eval = -float('inf') for move in get_legal_moves(board): board.push(move) eval = minimax(board, depth - 1, False) board.pop() max_eval = max(max_eval, eval) return max_eval else: min_eval = float('inf') for move in get_legal_moves(board): board.push(move) eval = minimax(board, depth - 1, True) board.pop() min_eval = min(min_eval, eval) return min_eval def evaluate_board(board): 手工打分:子力价值 + 位置价值 + 局面特征 score = 0 for piece in board.pieces: score += piece_value[piece.type] 车=1000,马=400,炮=400,兵=100... score += position_value[piece.type][piece.pos] 位置表 return score
这种实现方式有哪些致命问题?
评估函数靠“人工经验” :车值多少分?马在棋盘中心该加多少分?全靠程序员拍脑袋,难以覆盖棋局的复杂性。
深度受限:围棋分支因子约250,暴力到第5层就约100亿种局面,计算量爆炸。
没有学习能力:规则写死后无法自我进化,棋力上限被固定。
代码维护成本高:每个棋种都需要重写评估函数,几乎没有复用性。
这些痛点的本质在于——传统AI是在“模拟人类思考”,而下棋AI助手的突破在于“让机器自己学会思考”。
二、核心概念:蒙特卡洛树(MCTS)
蒙特卡洛树(Monte Carlo Tree Search, MCTS) 是一种基于随机模拟的启发式算法,通过“采样”而非“穷举”来评估决策价值。
用生活化类比理解MCTS
想象你要在一个新城市找一家好吃的餐厅。你不会试遍所有餐厅——那样太耗时。MCTS的做法是:
选择(Select) :先凭直觉挑几家看起来不错的店。
扩展(Expand) :进去点一个菜试试。
模拟(Simulate) :吃完打分。
反向传播(Backpropagate) :把评分带回记录,下次优先尝试得分高的店。
MCTS的四阶段流程
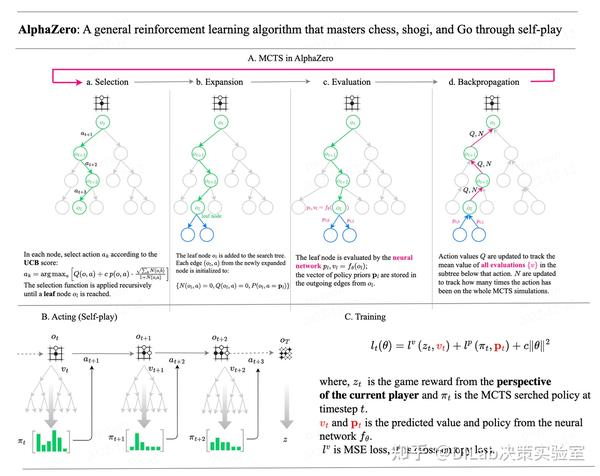
MCTS的每一次迭代都包含四个步骤-2:
1. 选择(Selection) :从根节点开始,根据 UCT(Upper Confidence Bound Applied to Trees) 公式选择子节点,平衡“利用(选胜率高的)”和“探索(选访问次数少的)”。UCT公式为:score = 平均胜率 + C × √(ln(父节点访问次数) / 节点访问次数)。
2. 扩展(Expansion) :到达叶节点后,若局面未结束,将该节点的合法动作作为子节点加入树。
3. 模拟(Simulation / Rollout) :从新节点开始,用快速走子策略随机模拟对局直至终局,得出胜负结果-7。
4. 反向传播(Backpropagation) :将模拟结果沿路径回传,更新路径上所有节点的胜率和访问次数。
MCTS解决了什么问题?
| 问题 | 传统算法 | MCTS解决方案 |
|---|---|---|
| 状态空间巨大 | 暴力指数爆炸 | 采样式,不穷举 |
| 没有评估函数 | 依赖手工打分 | 通过模拟获取结果 |
| 局部最优陷阱 | 贪心策略易早停 | UCT自动平衡探索与利用 |
三、关联概念:深度神经网络(DNN)
MCTS虽然强大,但有两个核心瓶颈:随机模拟效率低(纯随机下棋很难产生高质量评估),以及树初始化慢(面对新局面时缺乏先验知识)。
深度神经网络(Deep Neural Network, DNN) 恰好能解决这两个问题。
定义
深度神经网络是多层非线性计算单元组成的模型,能够从原始输入(如棋盘状态)中自动提取高阶特征,输出预测结果。
在下棋AI中的角色
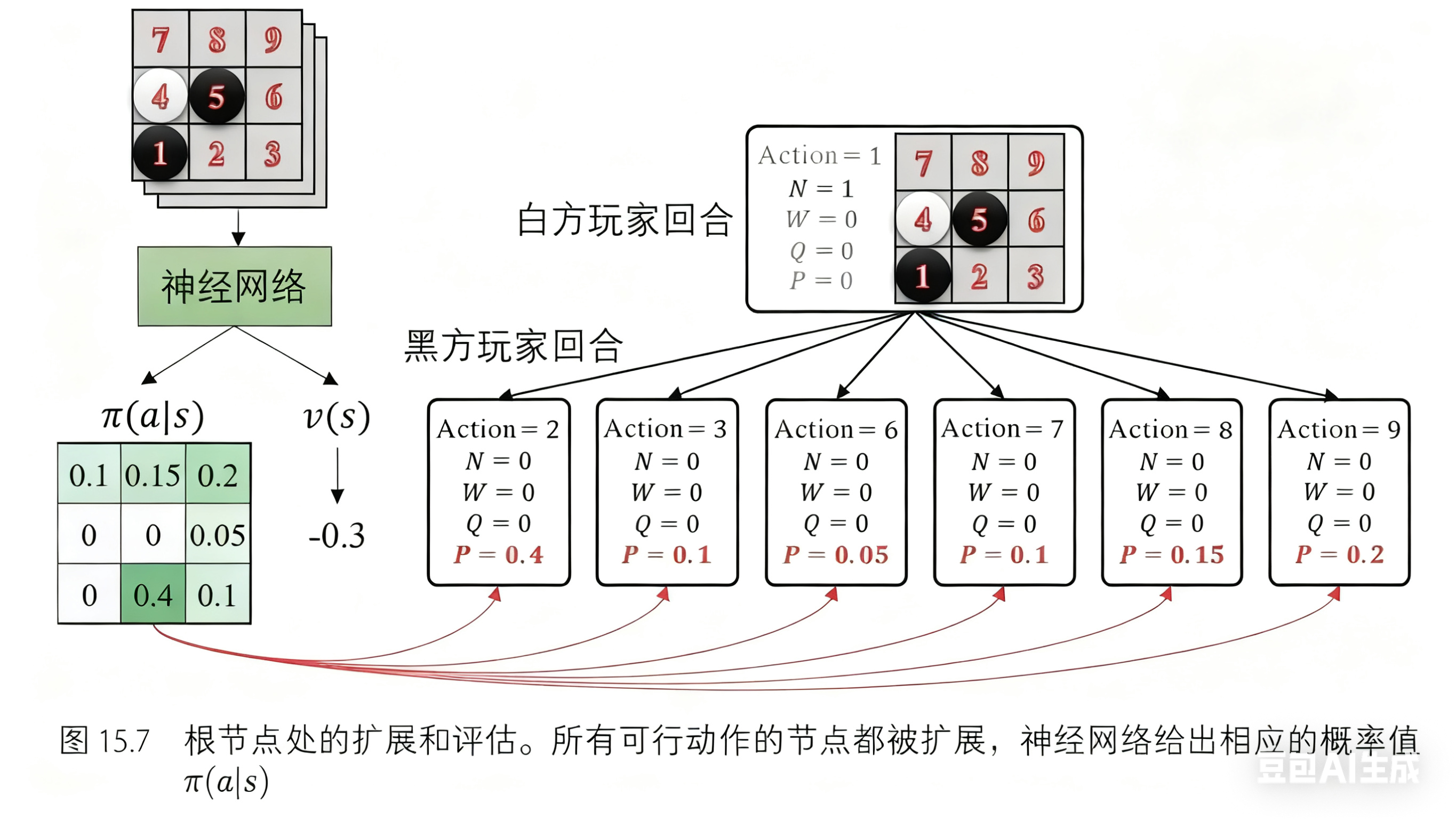
AlphaGo Zero采用的是一个统一的神经网络,同时输出两部分信息-30:
策略头(Policy Head) :输出一个概率分布,告诉MCTS每个落子位置有多大概率是好棋-7。
价值头(Value Head) :输出一个标量,评估当前局面的胜率。
MCTS与神经网络的关系
MCTS负责“” :在神经网络给出的“先验概率”指导下,聚焦于高潜力分支进行模拟。
神经网络负责“直觉” :快速评估局面,缩小空间,避免MCTS在无关分支上浪费时间。
可以这样理解:神经网络是AI的“快思考系统” (直觉、模式识别),MCTS是AI的“慢思考系统” (推理、验证)。两者协同工作,既保留了的严谨性,又利用了深度学习的模式识别能力。
四、概念关系总结
| 维度 | MCTS(蒙特卡洛树) | 深度神经网络 |
|---|---|---|
| 本质 | 算法 | 函数近似器 |
| 输入 | 树节点、UCT公式 | 棋盘特征张量 |
| 输出 | 落子概率(经修正后) | 策略分布 + 胜率估值 |
| 解决的问题 | 在巨大动作空间中高效 | 提供先验知识、压缩空间 |
| 是否需要先验知识 | 不需要,但有了效率更高 | 需要训练(自我对弈) |
一句话记忆:神经网络是“地图”,MCTS是“导航”——神经网络先画出哪些地方值得走,MCTS再沿着这些方向深入探索。
五、代码示例:极简MCTS实现
下面是一个最简MCTS的Python实现,适用于五子棋、井字棋等棋盘游戏。完整代码约50行,你可以直接复制运行:
import math import random from collections import defaultdict class MCTSNode: """MCTS树节点""" def __init__(self, state, parent=None, action=None): self.state = state 当前局面 self.parent = parent 父节点 self.action = action 到达此节点的动作 self.children = [] 子节点列表 self.visits = 0 访问次数 self.value = 0.0 累计胜率 self.is_expanded = False 是否已扩展 def ucb_score(self, c=1.41): """计算UCT分数""" if self.visits == 0: return float('inf') exploitation = self.value / self.visits exploration = c math.sqrt(math.log(self.parent.visits) / self.visits) return exploitation + exploration def best_child(self): """选择UCB分数最高的子节点""" return max(self.children, key=lambda c: c.ucb_score()) def mcts_search(root, num_iterations=1000): """MCTS主循环""" for _ in range(num_iterations): node = root 1. 选择 - 走到未完全扩展的节点 while node.is_expanded and node.children: node = node.best_child() 2. 扩展 - 若当前局面未结束,扩展一个子节点 if not is_terminal(node.state): node = expand(node) 3. 模拟 - 随机走子直到终局 result = simulate(node.state) 4. 反向传播 while node: node.visits += 1 node.value += result result为1(赢)或0(输) node = node.parent 返回访问次数最多的动作 return max(root.children, key=lambda c: c.visits).action def expand(node): """扩展一个新子节点""" legal_moves = get_legal_moves(node.state) node.is_expanded = True 简单起见,按顺序取第一个未扩展的动作 for move in legal_moves: if not any(c.action == move for c in node.children): new_state = apply_move(node.state, move) child = MCTSNode(new_state, parent=node, action=move) node.children.append(child) return child return node.children[0] fallback def simulate(state): """随机模拟对局(快速走子)""" curr_state = state while not is_terminal(curr_state): moves = get_legal_moves(curr_state) random_move = random.choice(moves) curr_state = apply_move(curr_state, random_move) return get_winner(curr_state) 返回1表示当前玩家赢,0表示输
关键步骤标注:
第35-37行:UCB分数公式中的
log(parent.visits)/visits项,平衡了“利用已发现的好棋”和“探索未知区域”。第55-59行:
simulate函数是MCTS的“思考”环节,随机走子的质量直接影响效果。第62-65行:反向传播把模拟结果带回根节点,让胜率信息在树中传播。
完整的棋盘逻辑(get_legal_moves、apply_move、is_terminal等)需要根据具体棋类实现。对于井字棋,约100次迭代即可获得接近最优的策略。
六、主流开源下棋AI引擎介绍(2026年更新)
如果你不想从零实现,直接使用成熟的开源引擎是更高效的选择。以下是2026年主流的下棋AI助手引擎:
1. KataGo(围棋)
截至2025年,KataGo仍然是网络上可用的最强开源围棋机器人之一-18。它采用类似AlphaZero的流程进行训练,并通过大量增强与改进实现了显著优势:在相同硬件条件下,效率比传统围棋AI提升30%以上;通过动态配置参数,可在“纯AI模式”与“人类风格模式”间无缝切换;完整的自我对弈训练流程支持从零开始培养专属模型-56。
2. Stockfish(国际象棋)
Stockfish 18以3759 Elo的等级分位居全球榜首,纯C++编写、约5万行代码,可在任何笔记本电脑上运行-12。其核心技术是 NNUE(Efficiently Updatable Neural Networks) 神经网络架构——仅约30个输入特征活跃(99.93%是0值),配合增量更新和int8/int16量化,在现代CPU上可实现约6000万次/秒的局面评估速度-12。
与基于深度神经网络的Lc0(Leela Chess Zero)相比,Stockfish虽用了更简单的神经网络(NNUE而非Transformer),但因每秒可评估1500倍更多的局面,依然领先约200 Elo-12。传统Alpha-Beta + NNUE的方式,在棋类游戏中依然具有很强的竞争力。
3. Leela Chess Zero(Lc0,国际象棋)
Lc0是AlphaZero思想在国际象棋领域的开源实现,使用深度神经网络和MCTS评估局面-11。采用1.91亿参数的Transformer神经网络,走棋风格更接近人类直觉-12。LCZero项目由Gary Linscott(也是Stockfish开发者之一)主导,完全开源免费-。
4. 皮卡鱼(Pikafish,中国象棋)
基于NNUE神经网络的中国象棋引擎,源自Stockfish,是当前棋力最强的开源中国象棋引擎-14。2026年1月31日最新版本对比2025年6月27日版本,ELO提升了约26分-14。支持Windows、Linux、MacOS多平台,并提供在线体验版本,无需安装即可对弈。
七、底层原理支撑
上述所有下棋AI助手的技术栈,底层依赖于以下几个核心知识点:
| 底层技术 | 在AI下棋中的作用 |
|---|---|
| 卷积神经网络(CNN) | 提取棋盘局部特征(如棋形、定式) |
| 残差网络(ResNet) | 解决深层网络梯度消失问题,支持数百层深度-56 |
| CUDA/GPU并行计算 | 加速神经网络推理,实现毫秒级响应 |
| 强化学习 + 自我对弈 | 无需人类棋谱,通过自我博弈生成训练数据-1 |
| 反向传播与梯度下降 | 优化神经网络参数,逐步提升决策质量 |
这些基础技术共同支撑了AI从“看到棋盘”到“做出决策”的完整链路,也是后续进阶学习(如模型压缩、分布式训练)的根基。
八、高频面试题
Q1:请解释MCTS的四个阶段及其核心思想。
考察点:能否清晰阐述MCTS的工作流程,强调“平衡探索与利用”这一核心思想。
参考答案:
MCTS包含四个阶段:
选择:从根节点出发,使用UCT公式递归选择子节点,直到到达未完全展开的节点。UCT公式 = 平均胜率 + 探索项,平衡利用已知好棋与探索未知区域。
扩展:在选中的叶节点上,添加一个未被访问的子节点。
模拟:从新节点开始,采用快速走子策略随机对弈至终局,获得胜负结果。
反向传播:将模拟结果沿路径向上传播,更新所有经过节点的访问次数和累计胜率。
经过多次迭代后,选择访问次数最多的动作作为最终决策。
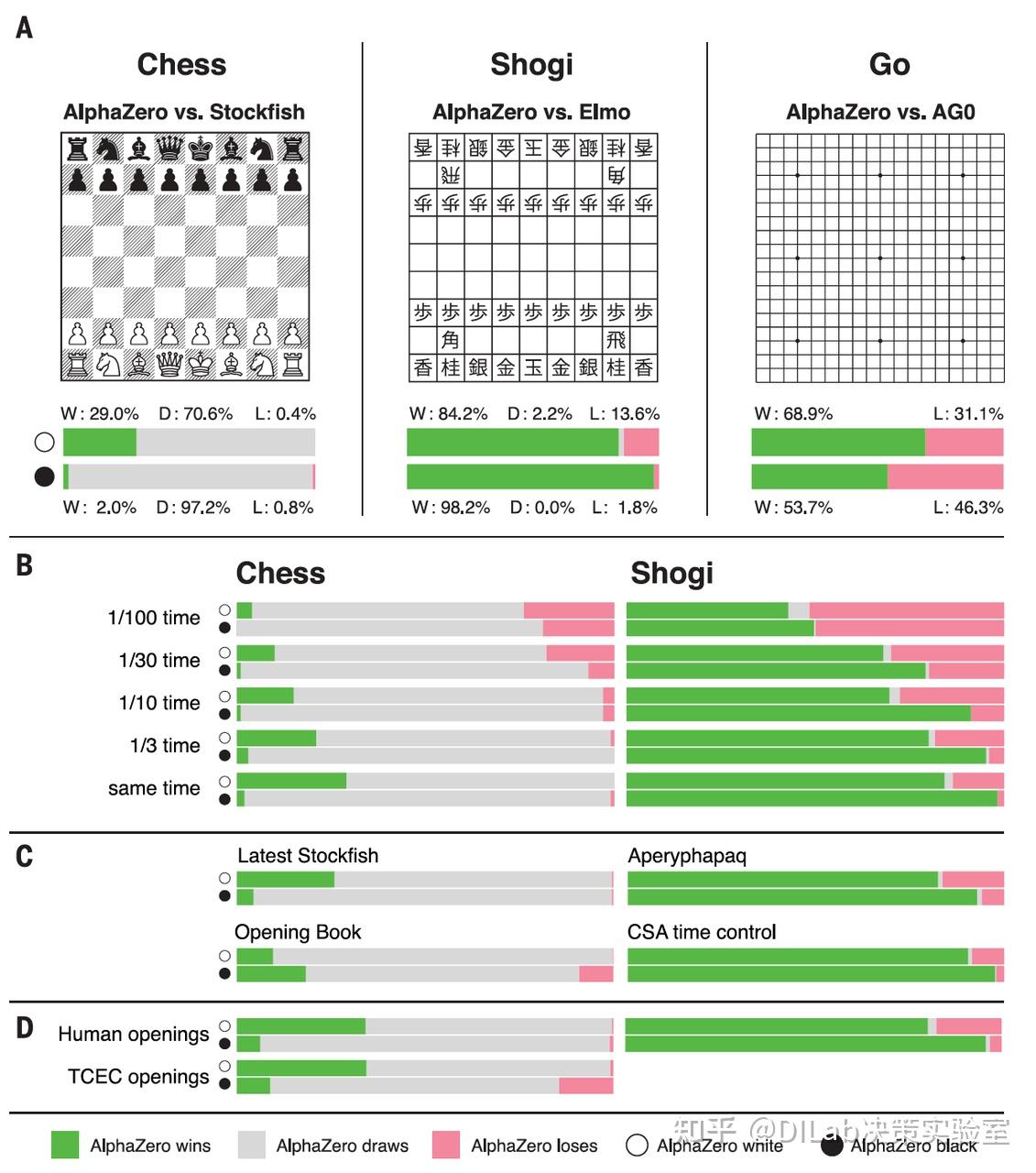
Q2:AlphaGo Zero相比前代AlphaGo的核心改进是什么?
考察点:理解AlphaGo Zero的革命性——摆脱人类知识依赖。
参考答案:
AlphaGo Zero的核心改进有三点-1:
无需人类棋谱:完全通过自我对弈(self-play)进行学习,摆脱了对3000万局人类棋谱数据的依赖。
单一神经网络:将前代的策略网络和价值网络合并为一个网络,同时输出落子概率和胜率估值。
输入特征简化:只使用黑白棋子的棋盘位置作为输入,不再使用任何人工设计的特征。
Q3:MCTS中UCB公式的探索项为什么用√(ln(N)/n)的形式?
考察点:对UCB公式数学含义的理解。
参考答案:
UCB公式的探索项√(ln(N)/n),其中N是父节点的访问次数,n是当前子节点的访问次数。这个设计的动机是:随着父节点访问次数N的增加,对数项增长缓慢,探索项整体逐渐减小;而子节点访问次数n越大,探索项越小。这样保证了每个节点最终都能被探索足够次数,同时随着进行,系统会逐渐从探索转向利用。√ 形式确保了探索项的衰减速度适中,这是经过理论证明的最优收敛速率。
Q4:什么是NNUE?它解决了什么问题?
考察点:了解现代国际象棋AI的技术前沿。
参考答案:
NNUE(Efficiently Updatable Neural Networks,高效可更新神经网络)是专门为棋盘游戏优化的神经网络架构-12。其核心创新在于:
稀疏激活:棋盘上仅约30个特征活跃,99.93%的输入为0,大幅减少计算量。
增量更新:每步棋只改变2-4个特征,不重新计算整个网络,而是原地更新累加器。
整数量化:使用int8/int16代替float32,配合CPU SIMD指令集加速。
NNUE使Stockfish在2020年一次性获得了约80-100 Elo的提升,相当于两年的常规开发成果。
Q5:如何在自己的应用中集成一个下棋AI助手?
考察点:AI落地实践能力。
参考答案:
集成下棋AI助手主要有三种方式-22:
SaaS API调用:通过HTTP请求调用云端AI服务(如
/v1/game/move),适合快速上线、无需运维的场景。SDK嵌入式集成:在客户端集成预编译AI SDK,实现离线对弈和毫秒级响应。
私有化部署:将Docker容器化的AI服务部署至内网,通过gRPC通信,满足数据合规要求。
关键技术组件包括:棋局逻辑引擎(提供规则校验、走法生成)、AI决策模型(MCTS + 神经网络)、状态同步机制(WebSocket + JSON Patch)。
九、总结与进阶预告
核心知识点回顾
MCTS是下棋AI助手的核心,通过选择-扩展-模拟-反向传播的循环,在巨大空间中高效决策。
深度神经网络为MCTS提供“直觉” ,输出策略概率和胜率估值,大幅压缩空间。
AlphaZero标志着技术范式转变——从依赖人类知识到纯粹的自我对弈学习。
开源引擎各具特色:KataGo(围棋)效率高,Stockfish(国际象棋)NNUE架构快,皮卡鱼(中国象棋)是国产最强。
底层依赖CNN/ResNet/CUDA/强化学习,构成了完整的技术栈。
进阶方向
模型压缩与轻量化:将大模型转化为可在移动端运行的轻量版(如TensorFlow Lite + ONNX)。
分布式训练架构:如何组织上千个分布式自我对弈节点,高效生成训练数据。
混合架构探索:MCTS + LLM大语言模型的结合——2026年已有研究尝试让AI agent自动生成新游戏规则-39。
下篇文章将深入讲解如何从零训练一个五子棋AI,包含完整的数据采集、模型设计、训练流水线代码,欢迎持续关注。
参考资源
AlphaGo Zero论文:Mastering the Game of Go without Human Knowledge(Nature,2017)
KataGo开源项目:github.com/lightvector/KataGo
Stockfish官网:stockfishchess.org
皮卡鱼:pikafish.com
LizzieYzy围棋分析界面:github.com/featurecat/lizzie