本文以AI诊疗助手的技术实现为核心,详解“大模型+医疗知识库(RAG)”四层架构,涵盖痛点分析、概念拆解、代码示例、底层原理与高频面试题。
在互联网医院、在线问诊平台快速普及的今天,
一、痛点切入:为什么“纯对话机器人”行不通
先看一个典型的错误实现——直接把患者问题抛给通用大模型:
❌ 错误方式:大模型直接回答 def wrong_diagnosis(patient_question): response = llm.chat(patient_question) return response
这种方式的致命缺陷在于:
幻觉严重——大模型可能编造不存在的疾病或疗法
回答不可控——无法约束模型给出合规、安全的回答
无法分诊——纯文本输出难以对接挂号、病历等业务系统
数据合规风险高——患者隐私直接暴露给模型API
核心结论:真正能上线商用的AI诊疗助手,一定不是“纯对话机器人”,而是“大模型 + 医疗知识库(RAG)+ 分诊规则引擎 + 医疗业务系统”的组合架构-1。
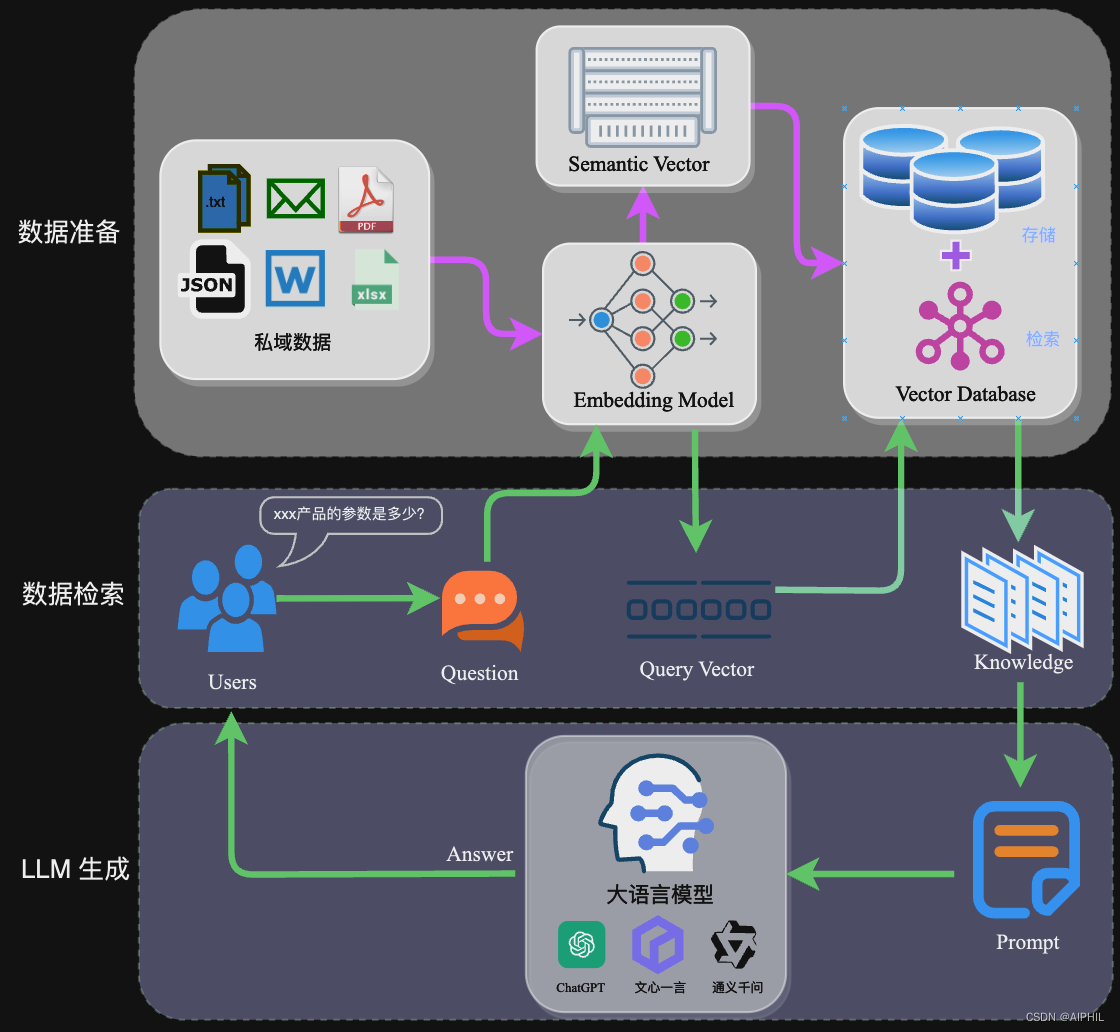
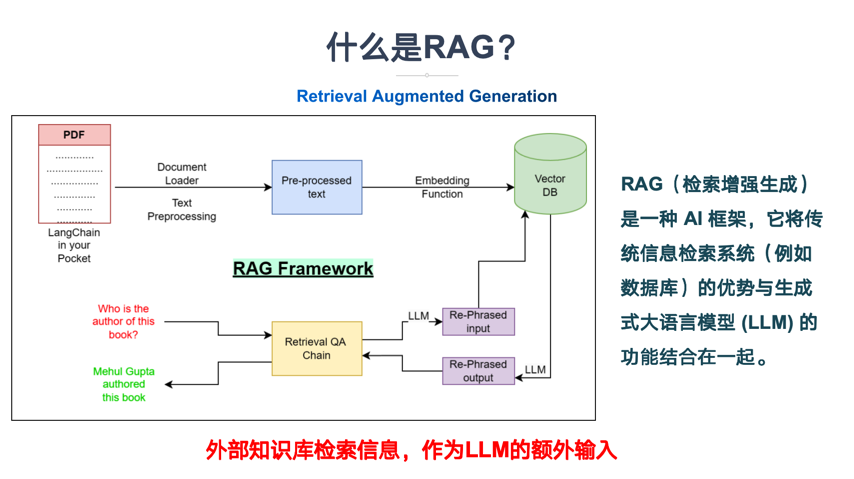
二、核心概念讲解:RAG(检索增强生成)
定义
RAG(Retrieval-Augmented Generation,检索增强生成) 是一种将信息检索系统与大语言模型相结合的技术架构——当用户提问时,系统先从一个可靠的知识库中检索出相关文档,然后将这些文档作为上下文“喂”给大模型,由模型基于这些证据生成答案。
拆解关键词
检索(Retrieval) :在知识库中与问题相关的内容
增强(Augmented) :将检索到的内容作为额外信息注入模型
生成(Generation) :模型基于检索到的证据进行回答
生活化类比
想象你要回答一个医学问题。RAG就像一位医生助理:他先去医学图书馆翻阅相关文献(检索),把找到的资料整理好放在你面前(增强),你再根据这些资料给出诊断结论(生成)。你永远不会凭空“猜”答案,而是让每一步都有据可查。
三、关联概念讲解:LLM(大语言模型)
定义
LLM(Large Language Model,大语言模型) 是一种基于海量文本数据训练而成的深度学习模型,具备理解、生成和推理自然语言的能力。
LLM与RAG的关系
RAG是架构方案,LLM是执行引擎
LLM负责“理解语言”和“生成回答”
RAG负责“提供证据”和“约束回答范围”
一句话概括:LLM决定“怎么说”,RAG决定“说什么” 。两者配合,才能让AI诊疗助手既有“口才”又有“学识”。
四、完整架构:四层设计
用户层(小程序 / App / H5) ↓ 问诊对话服务(Chat Service + Redis会话管理) ↓ AI能力层 ├── 大模型推理(LLM) ├── 医疗知识库(RAG + FAISS向量检索) ├── 症状识别NLP └── 分诊规则引擎 ↓ 业务系统层(医生排班 / 挂号 / 电子病历 / 处方)
核心思想只有一句话:LLM负责理解语言,知识库负责提供事实,规则引擎负责决策——千万不要让大模型直接“做判断” -1。
五、代码示例:从零搭建AI诊疗助手核心模块
5.1 构建医疗知识向量库(Python + FAISS)
from sentence_transformers import SentenceTransformer import faiss import numpy as np 1. 加载嵌入模型 model = SentenceTransformer("moka-ai/m3e-base") 2. 准备医学知识文档 docs = [ "发烧超过38.5度持续三天建议就医", "胸闷胸痛可能与心血管疾病有关", "儿童咳嗽超过一周需排查肺炎" ] 3. 生成向量并构建索引 embeddings = model.encode(docs) index = faiss.IndexFlatL2(768) 768维向量 index.add(np.array(embeddings).astype("float32"))
5.2 问题检索 + Prompt拼接
4. 检索相关医学资料 def search_knowledge(query): q_emb = model.encode([query]) D, I = index.search(np.array(q_emb).astype("float32"), 3) return [docs[i] for i in I[0]] 5. 拼接约束性Prompt def build_prompt(question, knowledge): context = "\n".join(knowledge) return f"""你是一名专业医生助理,只能依据以下医学资料回答: 资料:{context} 问题:{question} 请给出安全、保守、医学合规的建议。"""
5.3 会话上下文管理(Redis)
import redis import json r = redis.Redis() def save_session(uid, msg): key = f"chat:{uid}" history = r.get(key) history = json.loads(history) if history else [] history.append(msg) r.set(key, json.dumps(history), ex=3600) 1小时过期
这段代码做了什么:当用户描述“发烧三天”时,系统先到知识库中检索相关医学资料,然后将检索到的权威内容与用户问题一并交给大模型,强制模型“戴着镣铐跳舞”——只能基于检索到的资料回答,杜绝凭空编造-1。
六、底层原理支撑
AI诊疗助手的高效运行,依赖以下底层技术:
| 技术组件 | 作用 | 关键点 |
|---|---|---|
| Embedding模型 | 将文本转为向量 | 决定检索准确度 |
| 向量数据库(FAISS/Milvus) | 高效相似度 | 毫秒级检索 |
| 大语言模型(GPT/DeepSeek/Claude) | 语言理解与生成 | 决定回答质量 |
| RAG架构 | 检索+生成的融合 | 解决“幻觉”问题 |
| 规则引擎 | 分诊与决策控制 | 确保流程合规 |
RAG之所以有效,是因为它通过“证据锚定”机制,将模型的回答范围限制在可追溯、可审核的医学资料内,从根本上降低了大模型在医疗场景中的幻觉风险。
七、高频面试题与参考答案
Q1:什么是RAG?为什么在AI诊疗助手中必须使用RAG?
标准答案:RAG(Retrieval-Augmented Generation)是一种结合信息检索与大语言模型的技术架构。在AI诊疗助手中必须使用RAG,因为医疗场景对准确性要求极高,大模型单独使用时容易产生“幻觉”——编造不存在的医学信息。RAG通过先检索权威医学资料、再基于资料生成回答,实现了可追溯、可更新、可审核、可控来源四大要求,从根本上保证了回答的医学合规性。
Q2:大模型在医疗场景中面临哪些核心挑战?如何应对?
答案:三大挑战:①幻觉问题——模型编造不存在的疾病或疗法;②回答不可控——无法确保输出符合医学指南;③数据隐私风险——患者敏感信息泄露。应对策略:采用RAG架构约束回答来源;使用分诊规则引擎控制决策流程;通过本地化部署保护数据隐私。
Q3:如何评估一个AI诊疗助手的质量?
答案:从四个维度评估:①准确性——回答与医学指南的一致性;②可解释性——能否展示推理依据;③幻觉率——编造信息的比例;④安全性——输出是否可能对患者造成伤害。实测中,优秀的医疗大模型可将幻觉率控制在3%以下-71。
Q4:RAG检索效果差怎么办?请给出优化策略。
答案:①优化嵌入模型——使用领域微调的医学Embedding;②混合检索——结合关键词检索(BM25)与向量检索;③重排序(Reranker) ——用交叉编码器对Top-K结果精排;④元数据过滤——按科室、疾病类型等维度预过滤-32。
八、结尾总结
回顾全文,我们围绕AI诊疗助手的技术实现,重点梳理了以下核心知识点:
痛点认知:纯大模型在医疗场景中“幻觉”频发,无法直接商用
核心架构:四层设计(用户层→对话服务→AI能力层→业务系统层)
关键概念:RAG = 检索 + 增强 + 生成,LLM是执行引擎
代码要点:向量检索(FAISS)+ 会话管理(Redis)+ 约束性Prompt
底层依赖:Embedding模型、向量数据库、大语言模型三位一体
面试重点:RAG原理、医疗AI挑战、质量评估、检索优化策略
重点掌握:AI诊疗助手的核心设计哲学是“不让大模型直接做判断”——LLM负责理解,知识库负责事实,规则引擎负责决策。三者各司其职,才能构建安全、合规、可商用的智能诊疗系统。
下期预告:本文将作为AI诊疗助手技术系列的开篇,后续将深入讲解多智能体协作架构在复杂疾病诊断中的应用、微调(Fine-tuning)与RAG的选型对比,以及医疗大模型的合规部署与隐私保护实践,欢迎持续关注。
参考资料:阿里云开发者社区《AI问诊系统开发架构解析》、协和医学杂志《基于大语言模型的医疗智能助手应用研究进展》、DigitalDefynd《100 AI Healthcare Interview Questions & Answers》等。